
Introduction
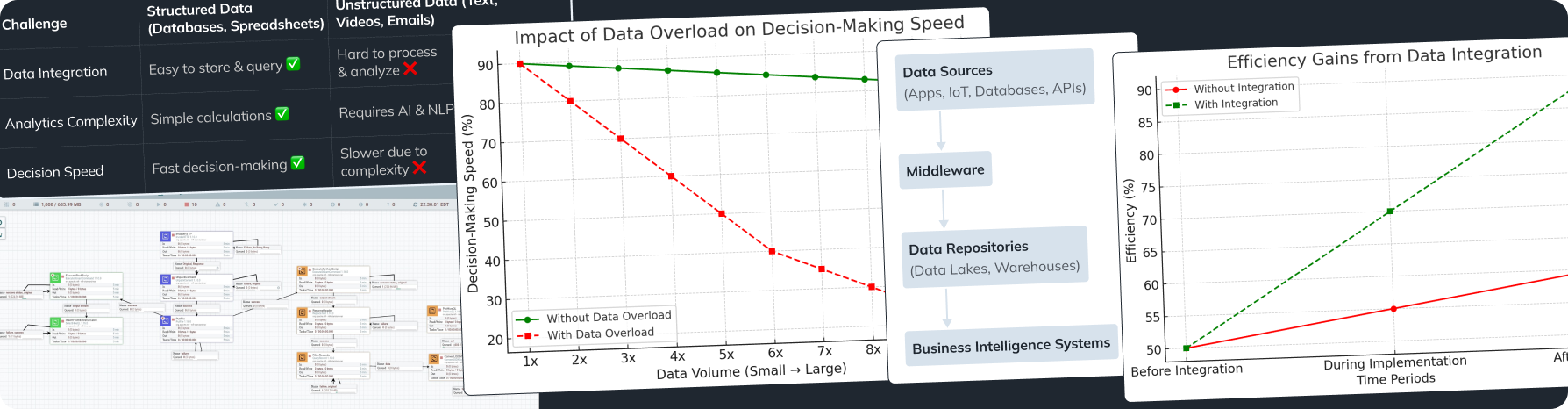
Understanding big data integration and why it matters can really help organizations manage and use their data better. Good data integration helps get useful insights and keeps operations running smoothly. Big data integration allows businesses to leverage vast amounts of information effectively. In this article, we will look at the five important steps for seamless data integration, the best tools and technologies to use, and useful tips for making sure your data is good and secure. Effective data integration techniques will also be discussed to aid in improving your processes.
Five Key Steps to Achieve Seamless Data Integration
Step 1: Data Collection – Determining the Available Data Sources

Data collection is the first step in any successful data integration plan. You need to create a clear list of all the data sources your organization has. This includes both organized data in databases and unorganized data like social media posts, emails, server logs, and external data from other companies. Additionally, for big data integration, exploring various data sources can lead to richer insights. Utilizing big data management strategies can enhance your data collection efforts.
What You Can Do:
Start by writing down all the potential data sources inside and outside your organization. Internal sources may include:
CRM Systems (e.g., Salesforce): These contain customer interaction data.
ERP Systems (e.g., SAP): These hold information related to business operations.
IoT Devices: Sensors and machines that collect real-time data.
External sources are also important and could be:
Social Media APIs: Like Twitter or Facebook, which give real-time updates and user feelings.
Public Databases: For industry-specific data or demographic information.
Third-party Vendors: Data from partners for analytics.
After documenting your data sources, gather metadata for each. Metadata means data about your data; it includes:
- Data Structure: The way data is organized, like databases or file formats (CSV, JSON, etc.).
- Size of Data: How much space each dataset takes, important for storage.
- Update Frequency: How often data is updated (e.g., real-time, hourly, daily).
- Storage Location: Where the data is kept, whether on local servers or in the cloud.
Documenting this information helps you understand how data flows, making it easier to decide how to integrate. Collecting diverse data during the process of big data integration is crucial for achieving robust insights. Implementing a solid data pipeline architecture can streamline the data flow.
Step 2: Data Cleaning – Methods to Maintain Data Quality

Data cleaning is vital to ensure that the data you integrate is correct, consistent, and trustworthy. If data quality is poor, it can hurt the insights you get from data analysis, leading to bad decisions. The role of data cleaning in big data integration is essential, as it creates a reliable foundation for analytics.
Things to Implement:
Use algorithms or scripts to find and remove duplicate records. You can automate this by:
Defining what makes a duplicate (like the same email addresses, names, etc.).
Using tools or programming languages like Python (pandas library) to remove duplicates effectively.
Set up rules to check entries against either pre-set data entry rules. For example:
Create validation rules in databases that stop incorrect formats (like a text field for a phone number).
Regularly check data against external reference databases to catch errors.
This ensures uniformity across data sets. For example:
Make all dates use the same format (e.g., YYYY-MM-DD) with scripts or tools in ETL (Extract, Transform, Load) software.
Normalize text data (like converting “NY” and “New York” to a common format).
Cleaning and preparing data before integration lays the groundwork for effective data analytics and supports successful big data integration. Furthermore, understanding the ETL processes in big data allows you to refine this aspect of your data management.
Step 3: Data Transformation – Approaches to Organize Data for Integration
Data transformation is necessary for arranging data in a way that makes it easy to integrate. The aim is to filter, group, and improve your data before sending it to a target database or analytics platform. In big data integration, transformation is key to ensuring all data aligns with your organizational needs.
Here’s How to Do It:
Data Mapping: Use data mapping tools to show how data fields connect between different sources. To do this:
- Identify key attributes from each data source that need to be integrated.
- Make a mapping document that shows how these fields relate to each other.
- Utilize data integration tools with visual interfaces to help with mapping—tools like Talend are great.
ETL Tools: Extract, Transform, Load (ETL) tools are used for a smoother data transformation process. For example:
- Talend: An open-source ETL tool perfect for beginners and experts. Set up tasks for extraction, specify transformation rules, and choose loading destinations.
- Apache NiFi: A powerful system that offers automation for complex data flows. Use its easy interface to design pipelines that extract data from many sources, apply transformations, and load it into databases.
Below are two additional steps—in the same format and tone—that you can seamlessly add as Step 4 and Step 5 to complete your guide on seamless data integration.
Step 4: Data Loading – Strategies for Putting Transformed Data to Use
After ensuring your data is cleaned and transformed, the next move is getting it where it needs to be—whether that’s a data warehouse, data lake, or an analytics platform. Effective data loading makes sure all users and applications can quickly access the insights they need. In big data integration, well-planned data loading procedures can significantly boost performance and reduce operational bottlenecks.
Here’s How to Do It:
- Choose the Right Destination:
- Relational Databases (e.g., MySQL, PostgreSQL): Ideal for structured data and transactional workloads.
- Data Lakes (e.g., Hadoop, Amazon S3): Perfect for storing high volumes of unstructured or semi-structured data.
- Data Warehouses (e.g., Snowflake, Redshift): Optimized for analytical queries on large datasets.
- Batch vs. Real-Time Loading:
- Batch Loading: Schedule bulk uploads during off-peak hours to avoid performance lags.
- Streaming/Real-Time Loading: Use tools like Apache Kafka or Amazon Kinesis for continuous data streams, ensuring near-instant updates.
- Automate & Validate:
- Automation Tools: Incorporate CI/CD pipelines or cron jobs to automate data loads, reducing manual effort.
- Validation Checks: Implement scripts to verify record counts, data formats, and integrity before and after loading.
Careful planning of the loading process avoids errors, data loss, and downtime. By refining your data loading pipeline, you set the stage for swift data access and robust big data integration.
Step 5: Data Governance & Monitoring – Ensuring Long-Term Quality and Compliance
Once your data is properly collected, cleaned, transformed, and loaded, the job isn’t over. Sustaining high-quality data requires continuous oversight. Data governance establishes the policies and processes to manage data’s availability, usability, and security. Meanwhile, continuous monitoring detects issues early, maintaining trust in your analytics. In big data integration, a strong governance framework is critical to handle large-scale, ever-evolving datasets.
Things to Implement:
- Define Governance Policies:
- Data Ownership: Assign clear roles (e.g., data stewards) responsible for data accuracy and usage.
- Compliance Requirements: Ensure alignment with regulations like GDPR, HIPAA, or CCPA for data privacy and protection.
- Standard Operating Procedures (SOPs): Document how data should be accessed, modified, and archived.
- Implement Monitoring Tools:
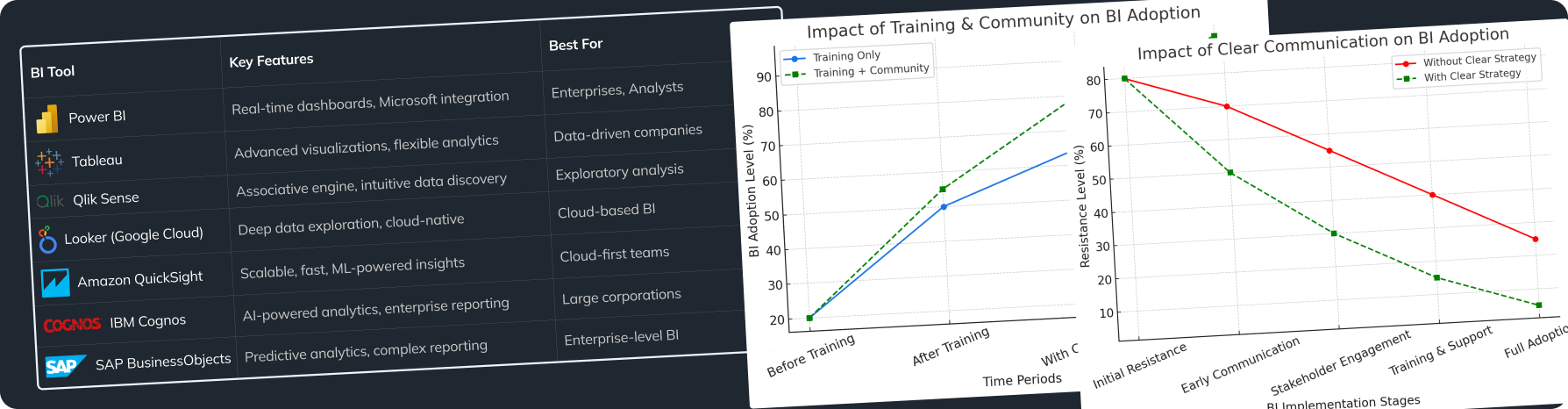
- Real-Time Dashboards: Tools like Grafana or Power BI provide live insights into data flow and quality metrics.
- Alerts & Notifications: Set triggers for anomalies, such as spikes in null values or unexpected data format changes.
- Regular Audits & Reviews:
- Metadata Auditing: Revisit metadata to confirm that data sources, structures, and update frequencies remain accurate.
- Performance Checks: Periodically evaluate query times and data pipeline speeds to ensure scalability.
By embedding governance into every part of your data lifecycle, you safeguard data integrity and ensure compliance with industry and regional regulations. Continuous monitoring further guarantees that your integrated data environment remains reliable and valuable for long-term analytics goals.
Use these five steps—Data Collection, Data Cleaning, Data Transformation, Data Loading, and Data Governance & Monitoring—to establish an end-to-end data integration pipeline. If you’re thinking about this topic, feel free to reach out for a free 20-minute consultation with a Dot Analytics expert!
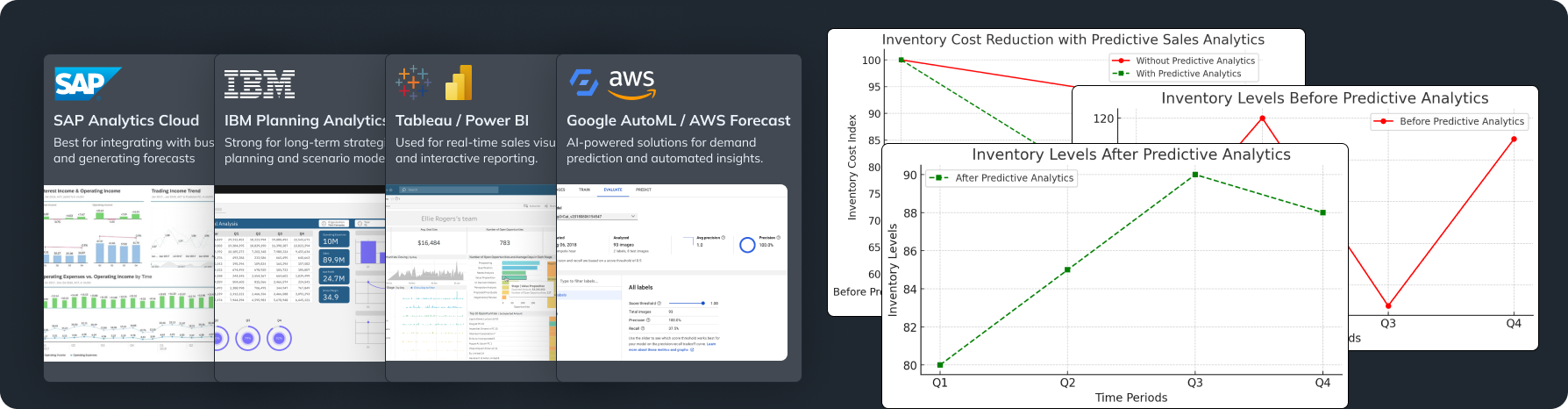
Recommended Tools and Technologies for Big Data Integration

Leading Big Data Integration Tools
Picking the right tools can make data integration much easier.
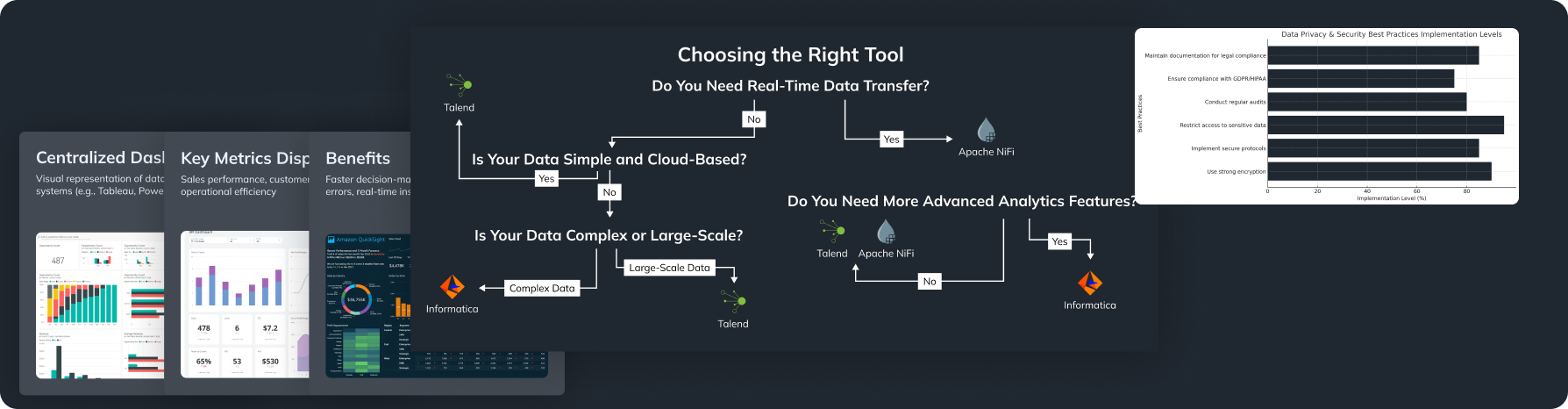
Apache NiFi:
What it Is?
A strong tool for data flow automation with a web interface.
Key Features:
It lets you visually define data flows, direct and change data, and set data priorities. It’s excellent for managing real-time data streaming.
Discover how Apache NiFi enhances big data integration capabilities for organizations.
How to Use:
Download NiFi from the Apache website, set it up according to instructions, and create a flow by dragging and dropping components and defining their properties.
Talend:
What it Is?
An ETL tool made to help with complex data integration tasks.
Key Features:
Talend has many pre-built connectors for various data sources and an easy-to-use interface for designing data pipelines.
Understand how Talend facilitates big data integration through its intuitive design.
How to Use:
Download Talend Open Studio for Data Integration, create a new job, and use drag-and-drop tools to connect to your data sources and set up transformation steps.
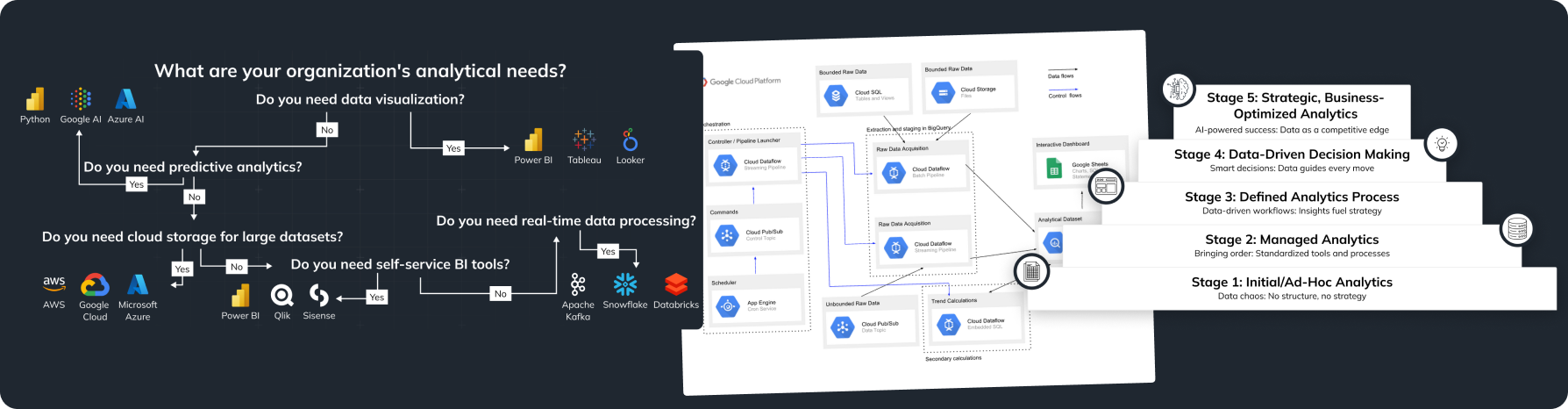
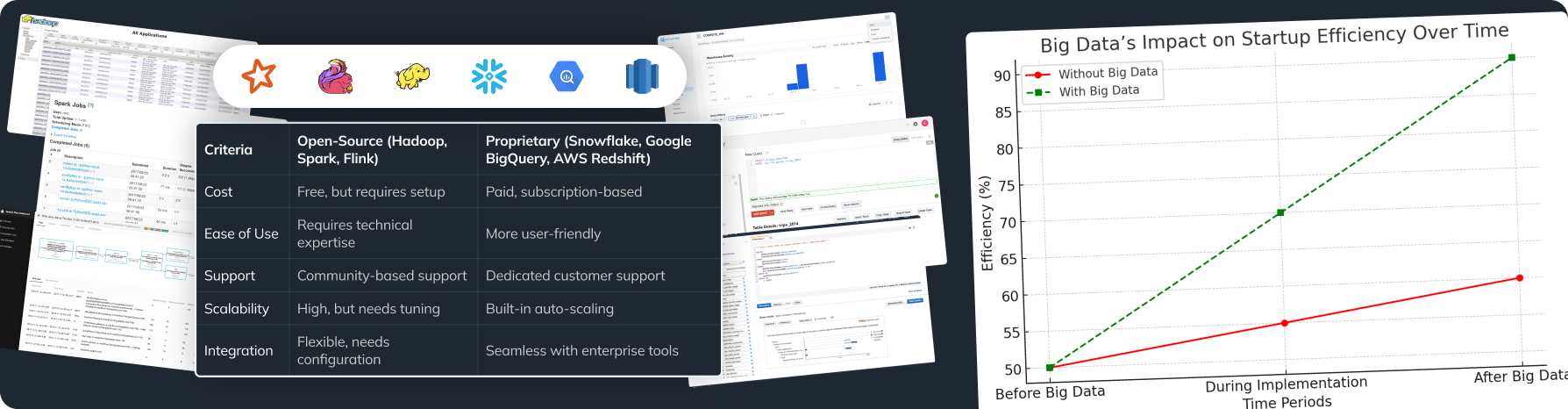
Cloud-Based vs On-Premises Solutions
Choosing between cloud solutions and on-premises systems really depends on what your organization needs.
Cloud-based Solutions:
- Pros: They can grow easily, allow remote access, and usually require less initial investment. Providers like AWS, Google Cloud Platform, and Microsoft Azure can manage your data without needing lots of hardware.
- Cons: Ongoing costs can add up, and some organizations may worry about where their data is stored. Always check your provider’s compliance with laws like GDPR.
On-Premises Solutions:
- Pros: You have complete control over your data security and compliance. This is very important if you have sensitive data or work in strict industries.
- Cons: Higher starting costs are usually needed, and scaling can take time.
Think about your data needs and choose the solution that meets your organization’s goals. Making informed decisions about big data integration is crucial for success.
Integration of New Technologies
Using Machine Learning (ML) or Artificial Intelligence (AI) in your data integration can bring big benefits.
How to Integrate ML and AI:
- Look for processes in data integration that are repetitive and could be automated.
- Use ML algorithms to find data anomalies or clean datasets, helping improve data quality post-integration.
- Advanced analytics platforms, like Google’s AI tools, can be used to make data integration easier.
If you’re unsure how to use these technologies for your organization, consider getting expert help. Taking advantage of ML and AI can streamline your big data integration processes.
Got questions? Connect with a Dot Analytics expert for a free 20-minute consultation and get your answers!
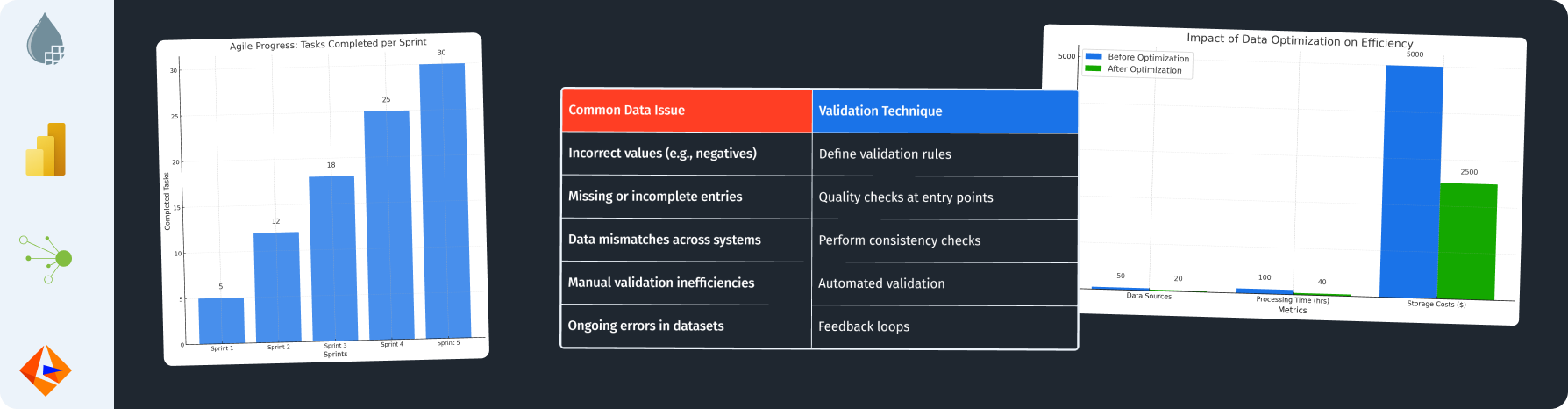
Assessing Data Quality Before Integration
Essential Metrics and Methodologies
To ensure successful data integration, you will need to closely assess your data quality.
Completeness:
Check if all important data points are available. For example:
- Find mandatory fields and run checks to ensure no critical information is missing.
- Use SQL queries or data profiling tools to mark incomplete records.
Consistency:
Compare datasets from different sources to ensure they match. Set up checks to find differences in how data is shown (like different formats for country codes).
Accuracy:
Check data entries against trusted sources. Here’s how:
- Run automated scripts that compare entered data to external datasets or check via APIs.
- Use validation rules to check for valid values (like dates that should fall within a certain range).
Instruments for Data Profiling
Use data profiling tools to help with checking your data quality. Tools like Talend Data Quality or Informatica can help find problems in your data.
- Steps to Use Data Profiling Tools:
- Import your datasets into the profiling tool.
- Set the profiling metrics you want to check (completeness, uniqueness, etc.).
- Schedule regular profiling checks to spot data quality problems over time.
Stakeholder Involvement
Getting stakeholders involved is key to keeping data accurate. Create a plan to involve them throughout the data assessment.
What to Do:
- Set up regular meetings to talk about data quality metrics.
- Document findings and share responsibilities for data quality.
- Train relevant stakeholders on daily data management and set data standards.
Getting users actively involved can greatly enhance data quality, which is essential for effective big data integration.
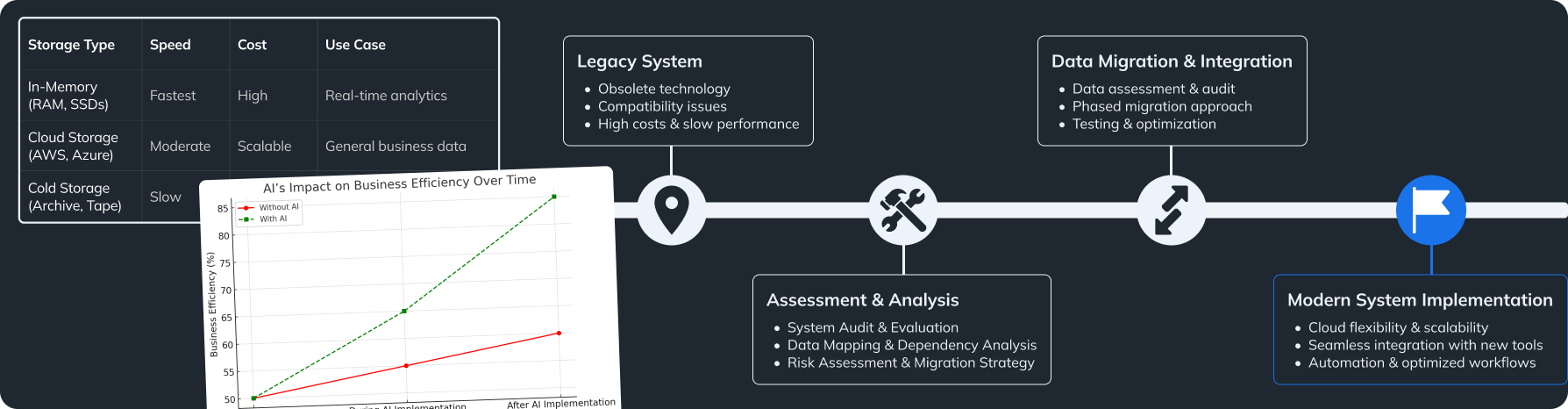
Common Challenges in Big Data Integration and Mitigation Strategies
Recognition of Obstacles
Big data integration often faces problems like data silos and format differences, which can make integration tough.
- Data Silos:
These happen when different departments don’t share their data. They can lead to duplication of effort and make it hard to make decisions based on data. - Format Inconsistencies:
Different data sources often use various formats (CSV, XML, JSON), which can cause problems when integrating various systems.
Techniques for Resolving Integration Complexities
- Cross-Functional Teams:
Create teams with members from different departments and technical backgrounds. This diverse knowledge helps tackle integration problems more effectively.
- Data Harmonization:
Use tools that support data harmonization to change data into a unified format automatically. This reduces errors and makes the integration process faster. Understanding these techniques is vital for a successful big data integration strategy. Additionally, applying enterprise data integration strategies may enhance overall organizational efficiency.
Case Study: NeoReach
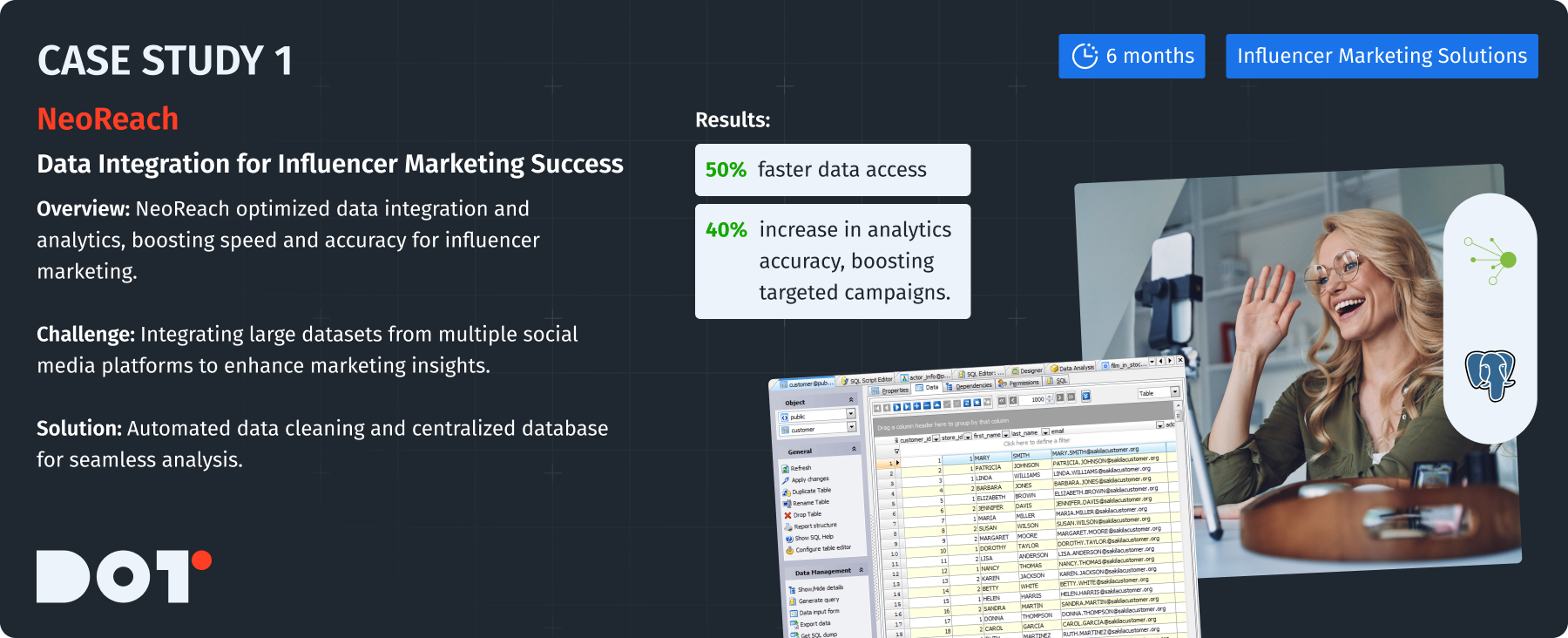
Company Overview:
NeoReach provides data-driven influencer marketing solutions to help brands succeed in their campaigns.
Challenge:
NeoReach had to integrate large datasets from various social media platforms, which was crucial for marketing insights.
Solution Description:
They used a mix of data cleaning and ETL tools to allow easy access to vital data for analysis.
What They Did:
- Made a centralized database that all departments could access.
- Automated the data cleaning process with Talend, greatly reducing errors and speeding up access.
How They Did It:
- Formed a specific team with data analysts and IT experts.
- The project took about 6 months with ongoing testing and feedback.
Technologies Used:
- Talend for ETL processes.
- PostgreSQL for data storage.
Results:
- Access time to data was cut by 50%.
- The accuracy of influencer marketing analytics increased by 40%, leading to better-targeted marketing campaigns.
Best Practices for Ensuring Data Security During Integration
Fundamental Security Protocols
Encryption: Encrypt data both when stored and when moved. This includes:
- Using SSL/TLS for data transfers.
- Setting up disk encryption where sensitive data is kept.
Access Controls: Use role-based access controls (RBAC) to limit who can access data based on their job roles.
- Regularly check permissions to make sure they are current and protect against unauthorized access.
Regulatory Compliance
Make sure to know the regulations for data management, like GDPR or HIPAA, and include compliance in your data integration plan.
- What to Check:
- Review your data handling rules to ensure they comply with legal standards.
- Train staff on the compliance protocols about data privacy and protection.
Auditing and Supervising Data Access
Regularly check data access records to see who is accessing what data. You can use automated tools for this to make it more efficient.
Steps to Implement:
- Define logging parameters based on the types of data being accessed.
- Set up alerts for unauthorized access attempts or unusual activities.
Measuring Success in Data Integration Efforts
Establishing Key Performance Indicators (KPIs)
Setting relevant KPIs helps track how well your data integration processes are working. Consider these metrics:
- Data Accuracy Rates: The percent of correct entries in your datasets.
- Data Processing Speeds: The time it takes to finish data transformations and integrations.
- Successful Data Loads: The number of data loads completed without errors.
Strategies to Gather Feedback
To improve integration processes:
- Conduct surveys or interviews with users after integration. Get their insights on usability and data quality.
- Use their feedback to implement changes and improve integration strategies.
Case Study: SchoolMessenger
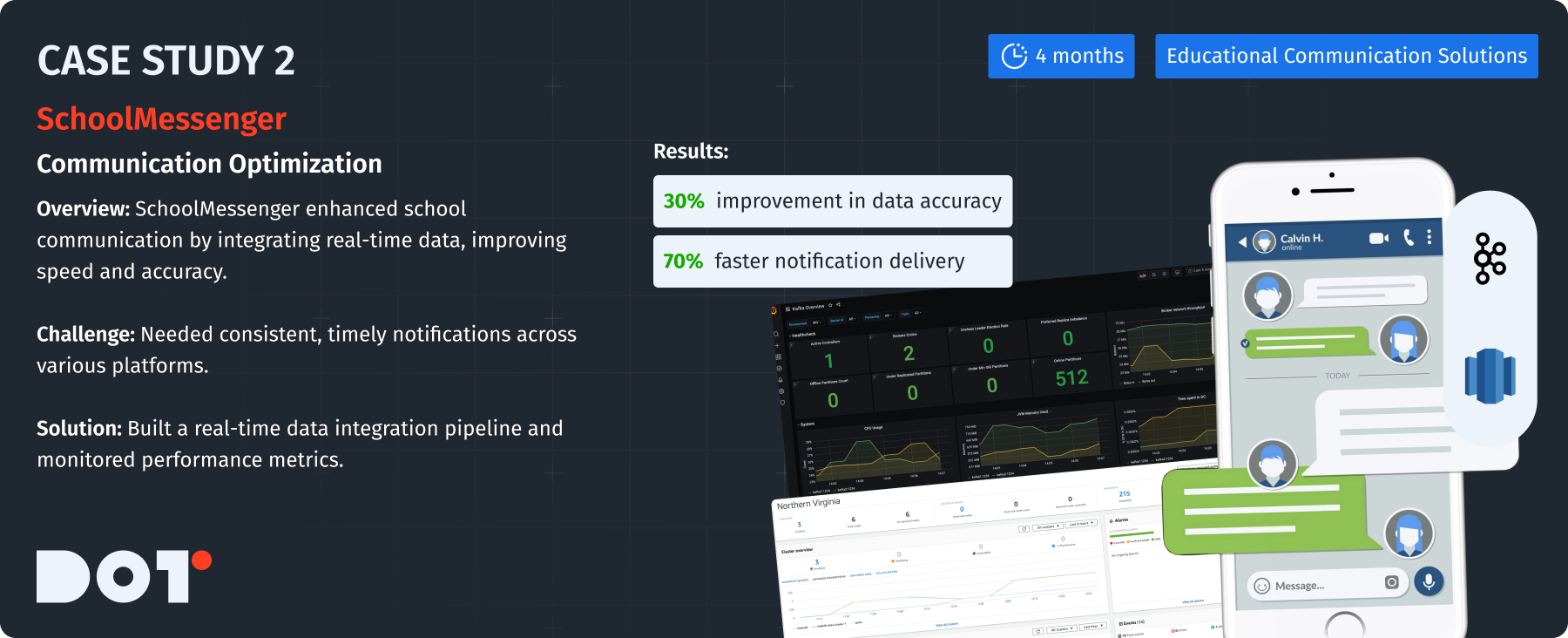
Company Overview:
SchoolMessenger focuses on communication solutions for schools.
Challenge:
They needed to integrate communication data from various platforms to send timely notifications.
Solution Description:
SchoolMessenger set up a strong data integration system to keep consistency across all communications.
What They Did:
- Created a real-time data integration pipeline to manage different data formats.
- Monitored key performance metrics to keep high data quality.
How They Did It:
- Involved diverse stakeholders like IT and education specialists.
- The execution took about 4 months, with continuous testing for better performance.
Technologies Used:
- Apache Kafka for real-time data streaming.
- Amazon Redshift for data analysis and storage.
Results:
- Improved data communication accuracy by 30%.
- Increased notification delivery speed by 70%, improving overall service.
Want to see how this applies to your business? Schedule a free 20-minute consultation with one of our experts!
The Role of Data Governance in Big Data Integration
Clarifying Data Governance
Data governance is about the rules, procedures, and standards for managing an organization’s data effectively. It helps keep data accurate, available, and safe. This is especially relevant in the context of big data integration.
Frameworks for Development
To create a good data governance framework, you can follow these steps:
- Define roles and responsibilities within the organization for managing data.
- Set rules for data quality metrics, reporting, and compliance.
- Include procedures for regular data use reviews and integrity checks.
Relationship with Data Quality
Data governance and data quality go together. Strong governance frameworks ensure:
- Ongoing collection of high-quality data.
- Setting standards for data entries to ensure everyone follows the rules in different departments.
By implementing effective data governance practices, organizations can enhance their big data integration efforts significantly.





















Leave a Reply