

Introduction
Data engineering challenges are very important for making strong analysis systems. Building good data pipelines helps organizations use their data well. But there are many challenges in developing these data pipelines, including common data pipeline issues that arise during the process. Understanding issues like data silos, integration problems, keeping data quality high, and ensuring security is important for any organization that wants to make the most of its data. These data engineering challenges can significantly impact operational efficiency if not addressed properly. This article looks at common data pipeline challenges, gives practical solutions, and shares tools and best practices to help you improve your data engineering work.
Common Challenges Encountered in Data Pipeline Development
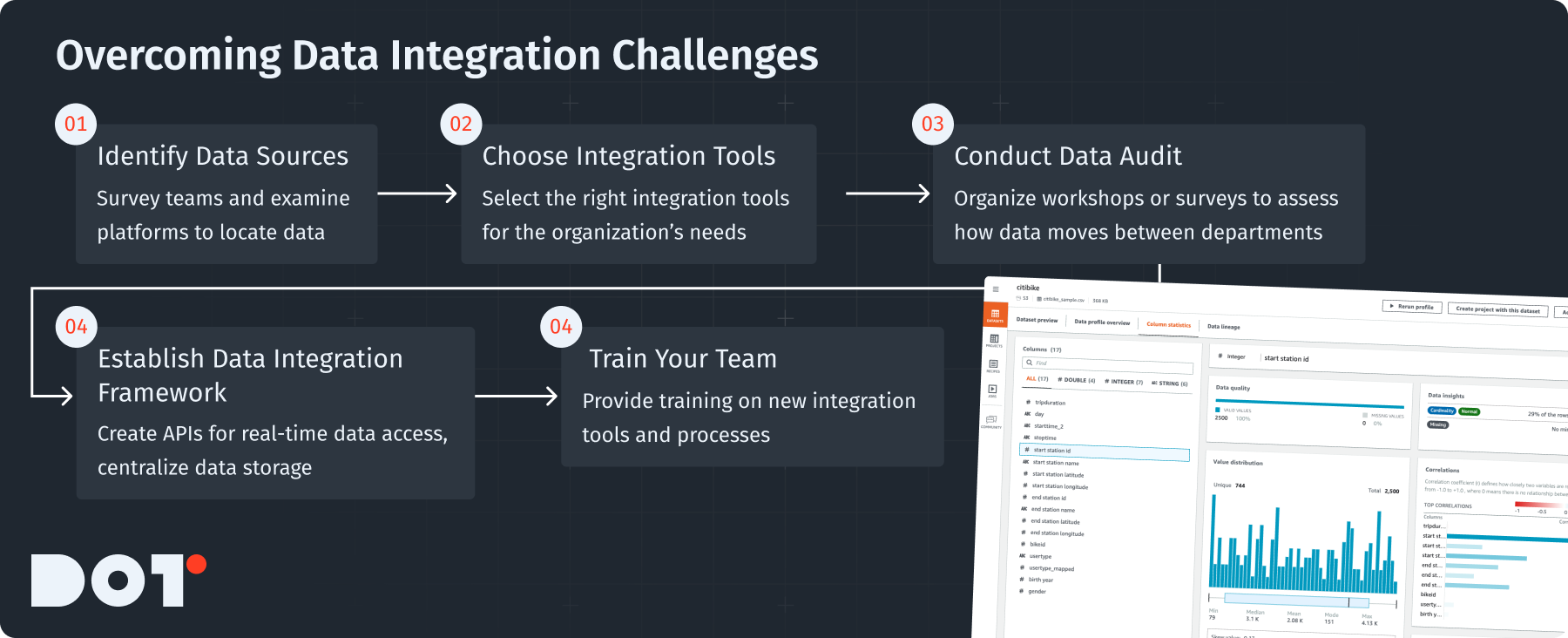
Data Silos and Integration Difficulties
Issue: Data silos make it hard to share information. Different departments might keep their data separate. For example, if one group manages customer information and another keeps transaction data apart, the knowledge needed to improve sales strategies can be lost. Overcoming these data engineering challenges requires a proactive approach to integration. Organizations often face data integration hurdles that further complicate the process.
Solution: It is essential to break down these silos. This can happen when departments share data easily and use shared systems.
What to Do:
- Identify Data Sources: Check all the data stored across different departments. Talk to important team members and look at various platforms. Addressing these data engineering challenges begins with knowing where all the data resides.
- Choose Integration Tools: Use tools that are good for integrating data. For example, Apache Kafka is great for moving messages between systems, and AWS Glue can help prepare data automatically.
How to Do It:
- Conduct a Data Audit: Use surveys or workshops to find out where data is located and how it moves between departments. This audit is crucial to tackling data engineering challenges.
- Establish a Data Integration Framework: Create APIs for real-time data access. Build a central place to store all data from different departments.
- Train Your Team: Provide training on new tools and ways to work together. Keep everyone updated on successes and new features to show the benefits of sharing data.
Changes in Schema and Data Format Challenges

Issue: When organizations change and grow, the data they use can change too, both in structure (schema) and type (format). For example, if a new system needs different data fields than an old one, problems can occur that disrupt the data pipeline. Failure to manage these changes can contribute to ongoing data engineering challenges, often leading to data quality problems.
Solution: Take steps to manage these changes before they happen. Using techniques to change data formats can help reduce issues, especially when dealing with big data challenges.
What to Do:
- Build Schema Flexibility: Create flexible models instead of hardcoding schemas. Use methods like JSON or XML that can easily change.
- Use Versioning: Use tools that keep track of different versions of data, so you can go back if problems arise. Proper versioning mitigates the data engineering challenges faced by many organizations.
How to Do It:
- Document Your Schemas: Keep a clear record of your data structure changes, and explain why they occurred and what they mean for the pipeline.
- Utilize Flexible Schema Management Tools: Use tools such as Apache Avro or Apache Parquet, which can adapt to changes in the schema.
- Establish Change Management Protocols: Make clear rules for communicating changes to teams involved in development and analysis.
Mechanisms for Error Handling and Recovery
Issue: Mistakes in data processing can lead to wrong analytics and data loss. This can lead to poor business decisions. For example, if a problem is wrongly flagged, a business may react to something that isn’t real. Tackling these data engineering challenges requires a structured error-handling strategy.
Solution: Create strong systems to handle errors and recover from them to keep your data trustworthy.
What to Do:
- Log Errors: Set up strategies to record and categorize mistakes in data processing.
- Enable Automated Recovery: Make your data pipelines automatically retry tasks when they fail to save time. This automatic retry process is vital for overcoming data engineering challenges in processing.
How to Do It:
- Adopt a Monitoring Tool: Use tools like Grafana or Elastic Stack to get real-time views of error logs.
- Write Optimistic Retry Logic in Scripts: When writing data processing codes, add logic to retry something if it fails.
- Set Up Alerts: Create notifications for when error logs reach a certain point, making it easy to spot and fix issues.
Maintaining Data Quality Throughout the Data Pipeline
Techniques for Data Validation
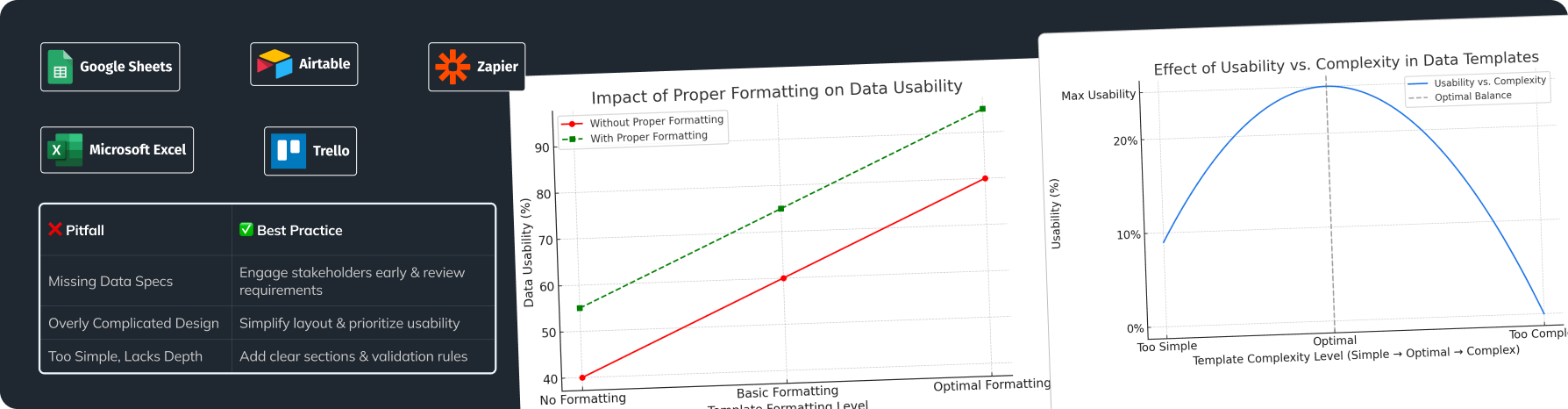
Ensure you check data carefully at each point of entry in your pipeline. This helps guarantee only accurate and important data reaches the analysis phase. Set rules based on what you expect, such as data ranges and types. Regular validation can help overcome data engineering challenges related to data accuracy.
Processes for Data Cleaning
After validating, use cleaning methods to remove duplicates, fix errors, and eliminate irrelevant data. You can use automated scripts in languages like Python or R to find duplicates or mistakes, thereby addressing some common data engineering challenges.
Monitoring Quality Metrics of Data
Create key performance indicators (KPIs) for your data quality. Focus on accuracy, completeness, and timeliness. Use dashboards to visualize these metrics and set up alerts for any drops from wanted standards. Continuous monitoring helps in identifying data engineering challenges early on.
Need Help with Data Engineering Challenges?
If you’re unsure about your data quality processes, you can book a free 15-minute consultation with an expert from Dot Analytics. Our team can help you review your current setup and suggest improvements.
Suggested Tools and Technologies for Building Robust Data Pipelines
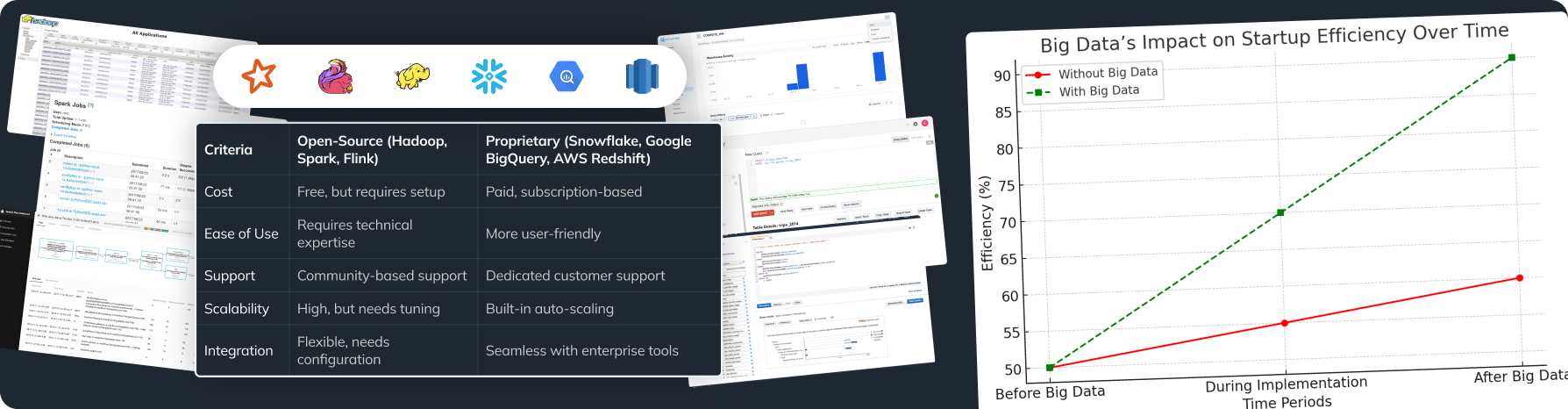
Open Source Solutions
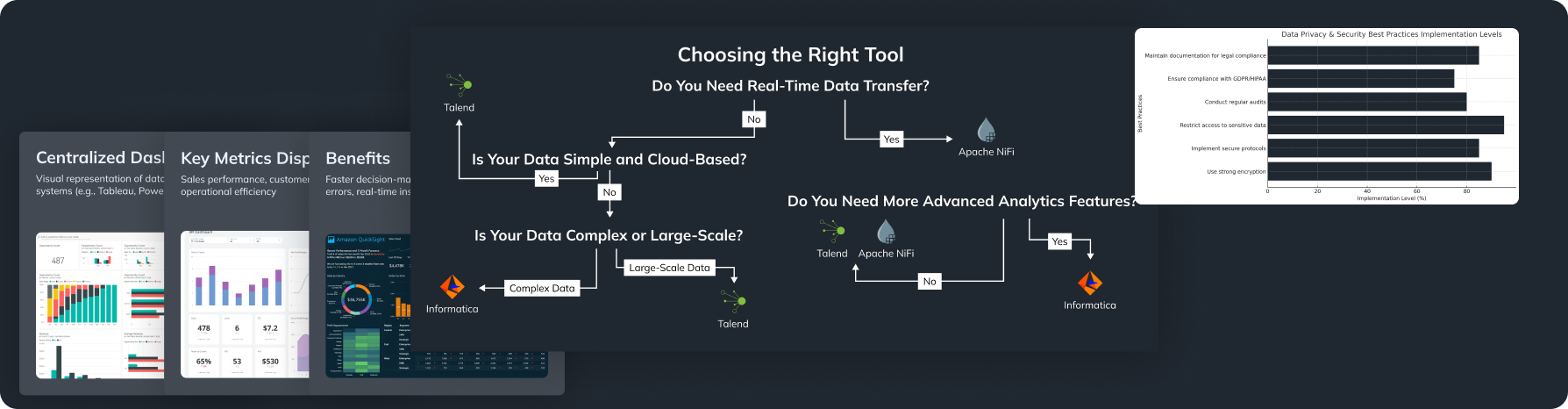
If you want to use available tools, Apache Kafka and Apache Spark are two great options. Apache Kafka helps share real-time data between programs, and Apache Spark lets you process large amounts of data easily while tackling data engineering challenges efficiently.
Cloud-Based Platforms
Modern services like AWS Glue and Google Cloud Dataflow make it easier to handle data at scale. AWS Glue helps automate the organization of data, while Google Cloud Dataflow allows processing data streams in real-time, solving many data engineering challenges in cloud environments.
ETL Solutions

Tools such as Talend and Apache Airflow are excellent for managing data workflows. Talend helps connect data from various sources, while Apache Airflow lets you schedule tasks and monitor their progress smoothly as part of overcoming data engineering challenges.
Enhance Your Business
If you want to know how these tools can fit into your business strategies, feel free to schedule a free 20-minute consultation with our experts. We will help you find the right tools for your organization’s needs.
Addressing Performance Issues in Data Pipelines
Locating Sources of Latency
Finding where delays happen is key to improving performance. Start by looking closely at your data pipeline parts to see which ones work slowly. Use tools like Grafana to track processing times and their effects. Identifying these performance metrics is essential to tackle data engineering challenges effectively, especially when faced with real-time data processing difficulties.
Enhancing Resource Distribution
Make sure resources are used wisely to avoid performance issues. For example, use cloud features to dynamically share workloads based on incoming data amounts, which helps with scaling in data engineering.
Techniques for Query Optimization
To make data access quicker, check and refine your queries. Use indexing and caching techniques to speed things up. Materialized Views can also help for commonly accessed data.
Securing Data During Processing Stages
Practices for Data Encryption
Keeping sensitive data safe is very important. Encrypt your data both while stored and during transmission, using AES (Advanced Encryption Standard) for solid security.
User Permissions and Access Control
Use strict rules to limit who can access sensitive data. Role-based access control (RBAC) is a smart way to assign user rights based on their role, limiting their access to only what they need. Security plays a crucial role in addressing data engineering challenges, including data governance challenges.
Logging and Audit Trails for Accountability
Keep detailed records of data access and actions taken. Use automated logging and perform regular checks to spot any wrongdoing, ensuring responsibility and transparency.
Observation and Maintenance of Data Pipeline Health
Establishing Alerts for Anomalies
Set up alerts for important metrics to catch any issues quickly. You can use tools like Prometheus to get notifications when performance metrics drop below set targets. This proactive approach helps mitigate potential data engineering challenges.
Conducting Regular Performance Reviews and Health Checks
Plan regular performance checks to evaluate how your pipeline is doing. Check metrics like error rates and processing times, and provide ideas for ongoing improvements.
Using Monitoring Tools
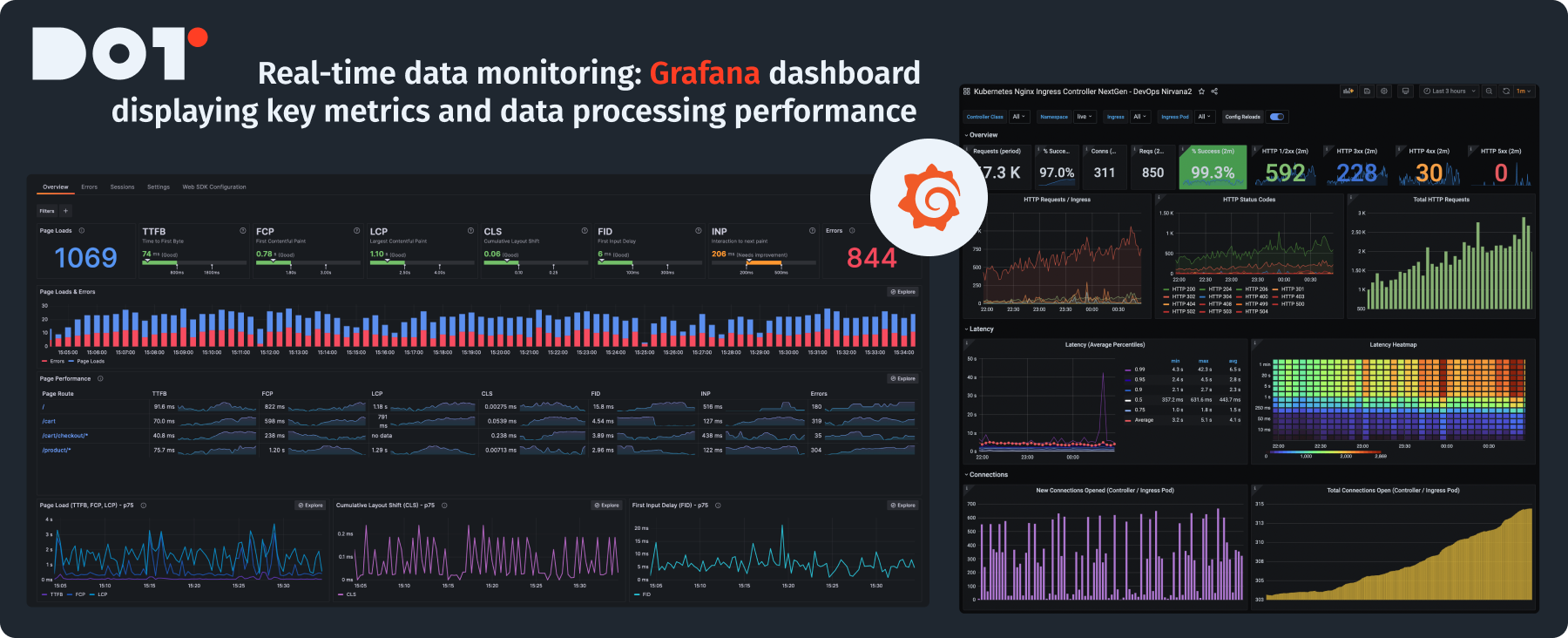
Use reliable monitoring tools to keep track of your data pipeline performance live. For example, Grafana allows you to visualize performance and alerts for critical metrics, so your team knows how well the pipeline is functioning anytime.
Methods for Seamless Data Integration from Different Sources
Employing APIs for Immediate Integration
To ensure fast integration, use APIs that let different systems talk to each other. A RESTful approach makes connections smoother and allows real-time data sharing, which is vital for solving data engineering challenges.
Adopting Data Lakes for Flexible Storage
Using data lakes helps store various raw data types flexibly. This is especially useful for handling unstructured data and keeps your data organized for later use.
Uniforming Data Formats for Compatibility
Standardize data formats across sources to make integration easier. Using uniform formats like JSON or Avro can make linking different systems simpler and ensure all data connects easily. This standardization can be a key factor in overcoming data engineering challenges.
Case Study: Impact.com – Conquering Data Integration Challenges
Issues Encountered in Partnership Data Management
Impact.com faced serious data integration problems because different companies used different methods to manage their data. This led to inconsistencies and delays in reporting, hurting their operations. They recognized that addressing these data engineering challenges was essential for success.
Instruments and Strategies Used for Integration
To fix these challenges, Impact.com used Apache Kafka for real-time data flow and synchronization with partner systems. This made it possible for data to move smoothly and helped improve decision-making speed and accuracy.
Outcomes Achieved in Data Pipeline Efficiency
- Team Composition: Made up of 5 Data Engineers and 2 Data Analysts.
- Project Duration: It took six months to build an effective data integration system.
- Technologies Used: Mainly used Apache Kafka and AWS S3 for storage.
- Results: They saw a 50% cut in data processing time and a 30% rise in data accuracy, improving their ability to manage partnerships.
Case Study: fuboTV – Enhancing Real-Time Data Processing
Performance Challenges Faced During Streaming
During busy viewing times, fuboTV experienced lag that ruined the user experience. Slow processing led to buffering and drop-offs, prompting a need for real-time solutions, highlighting the real-time data processing difficulties they faced.
Strategies Applied to Improve Data Pipeline Efficiency
fuboTV used Apache Spark for advanced data stream processing, which let them analyze data efficiently in real time. They also improved their cloud setup by moving to AWS for better scalability during peak times.
Effects on User Experience and Business Insights
- Team Composition: The project involved 8 Data Engineers and 3 Data Scientists.
- Project Duration: It took four months to implement these strategies.
- Technologies Used: Mainly depended on Apache Spark and AWS EC2.
- Results: These changes resulted in a 40% reduction in lag, leading to a 20% increase in viewer engagement and higher subscriptions and ad revenue, showing how data efficiency impacts user happiness.

Best Practices Checklist for Data Pipeline Management
Checklist Items
- Define Metrics: Clearly outline and track performance and data quality metrics.
- Quality Standards: Set high standards for data integrity and security, and ensure everyone knows the documentation.
New Topic: Expert Insights on Data Pipeline Challenges
Industry Trends and Innovations in Data Engineering
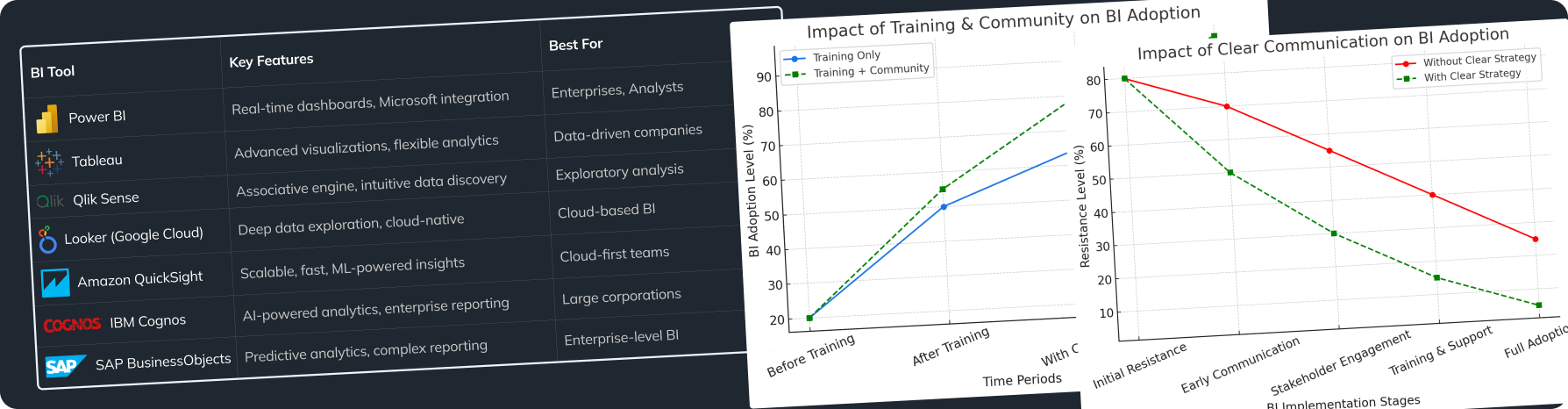
Stay updated on trends like low-code and no-code data tools. These innovations are making it easier for teams without a deep technical background to set up data pipelines and are essential in addressing data engineering challenges.
Best Practices from Leading Data Engineers
Top data engineers highlight the need for modular pipeline designs, focusing on data quality, and encouraging a culture of ongoing learning among teams, which helps overcome common data engineering challenges.
Summary of Data Engineering Challenges
In this article, we explored the many challenges faced while developing data pipelines. We learned how crucial it is to integrate data well, maintain data quality, and use technology smartly to resolve data pipeline issues. Understanding the tools available and following the right practices help navigate these data engineering challenges effectively.
Contact Information
If you have questions about data pipelines or need tailored advice, we welcome you to connect with a Dot Analytics expert. Schedule a free 20-minute consultation to get clarity on your concerns and learn how to optimize your data processes effectively.




















Leave a Reply