

Overview of Data Science Automation
In today’s technological landscape, data science automation transforms how organizations handle vast amounts of data. Businesses can optimize workflows and focus on strategic decision-making by automating repetitive and complex tasks. This shift accelerates data analysis and enhances the accuracy and scalability of data-driven decisions.
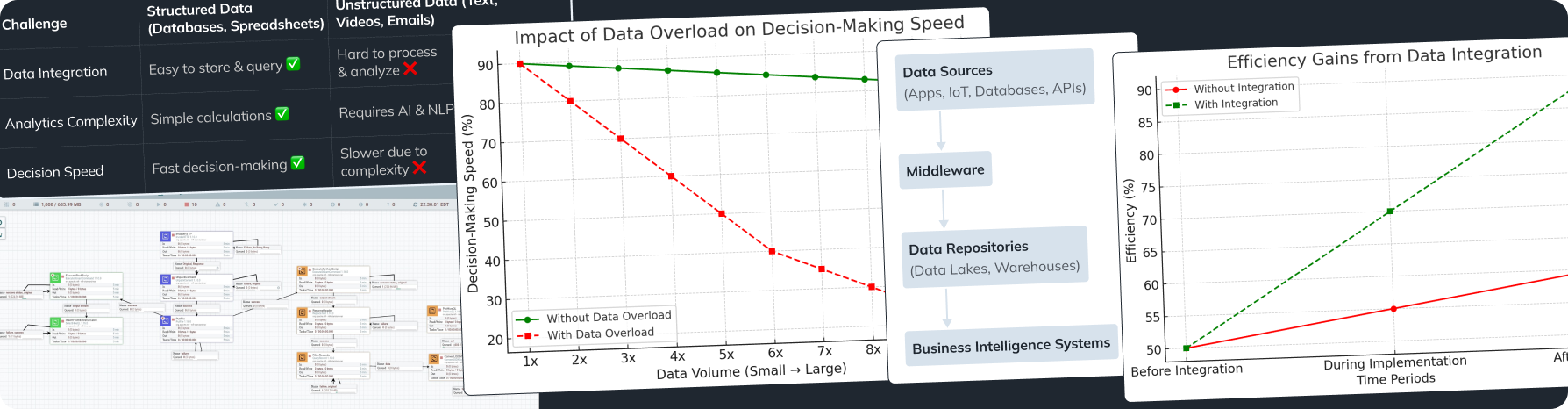
As companies grapple with increasing volumes of information, automating data workflows has become essential. Data science automation helps manage resources effectively, integrating analytics platforms and advanced capabilities to ensure timely and actionable insights. This approach streamlines operations and positions organizations to respond swiftly to market changes.
What is Automation in Data Science?
Definition and Scope
Automation in data science refers to the use of tools and technologies to streamline the data science pipeline—from data collection and cleaning to model building and deployment. It involves automating tasks that traditionally require manual intervention, reducing the potential for human error and speeding up processes.
Core Components
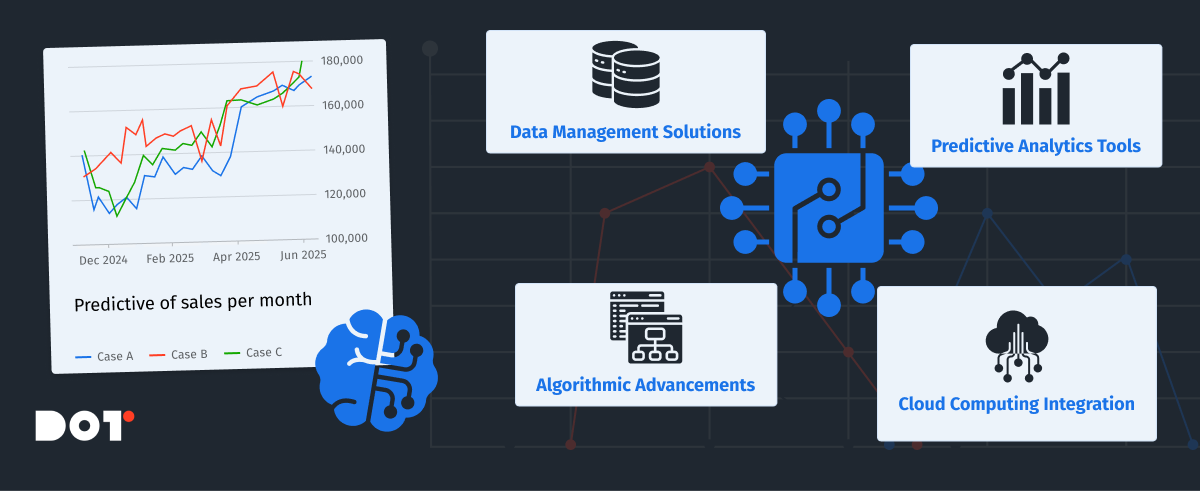
The core components of data science automation include:
- Data Management Solutions: Automating data collection, storage, and retrieval to handle big data efficiently.
- Predictive Analytics Tools: Utilizing algorithms that can learn and make predictions with minimal human input.
- Algorithmic Advancements: Implementing cutting-edge algorithms that require less manual tuning and can adapt to new data.
- Cloud Computing Integration: Leveraging cloud resources for scalable computing power and storage, facilitating access to advanced analytics capabilities without significant infrastructure investment.
Data Science Automation Tools and Techniques
Overview of Tools
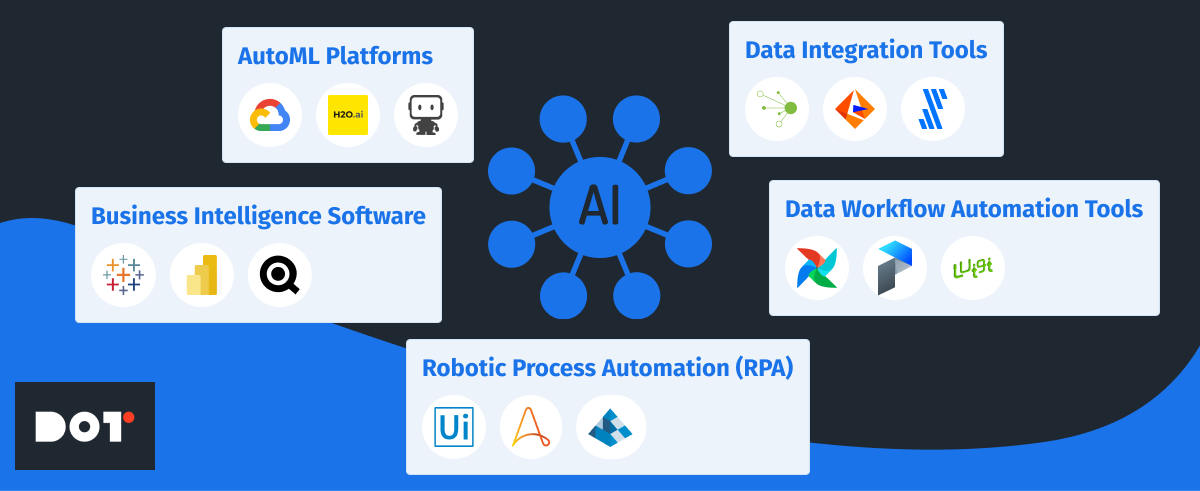
A variety of data science automation tools are available in the market, each offering unique features:
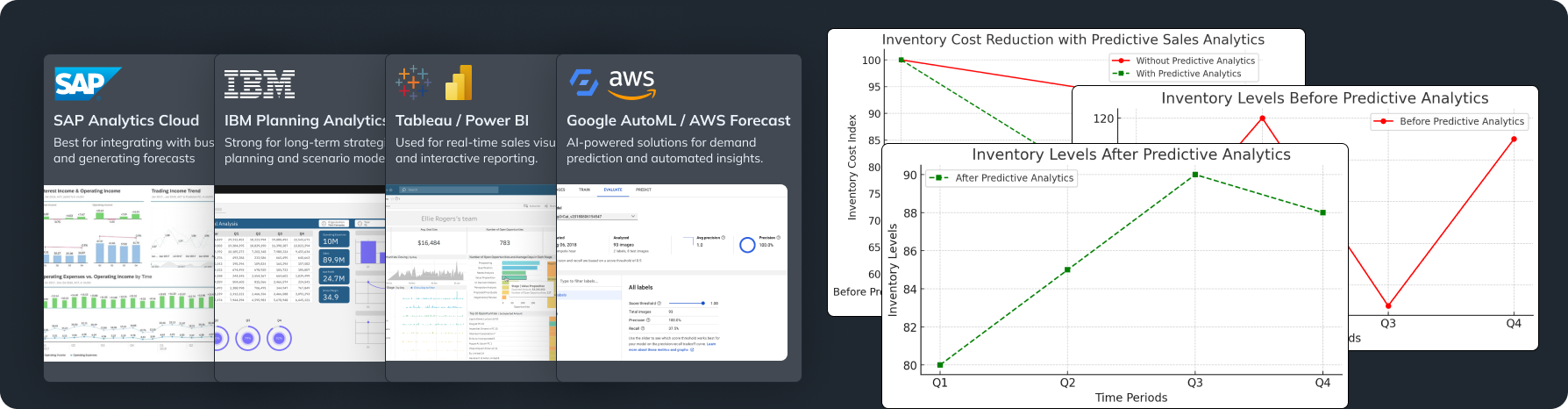
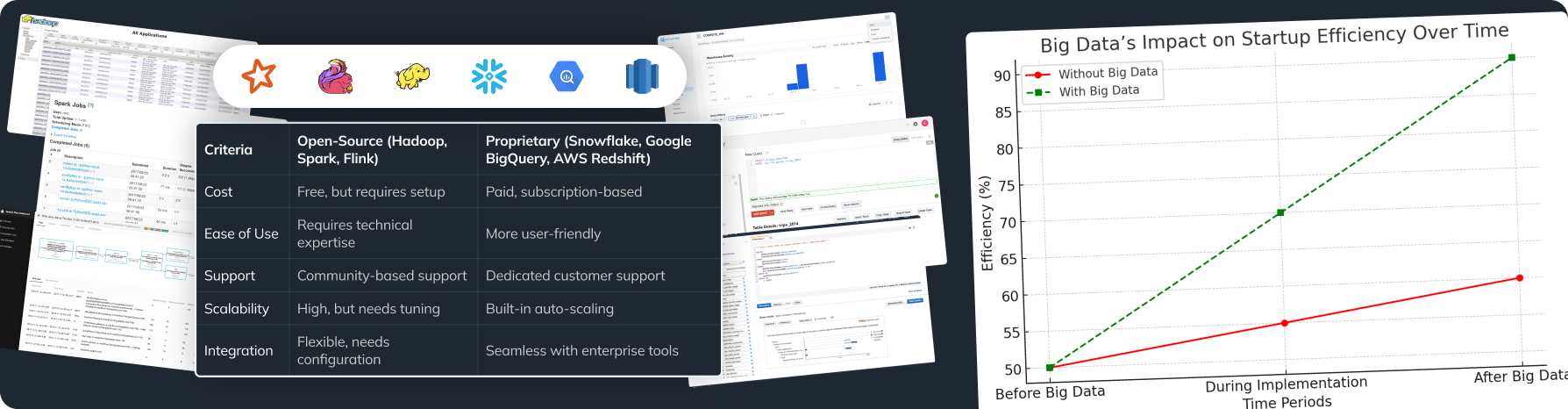
- AutoML Platforms: Tools like Google Cloud AutoML, H2O.ai, and DataRobot automate machine learning model selection and hyperparameter tuning, making it easier to develop accurate models quickly.
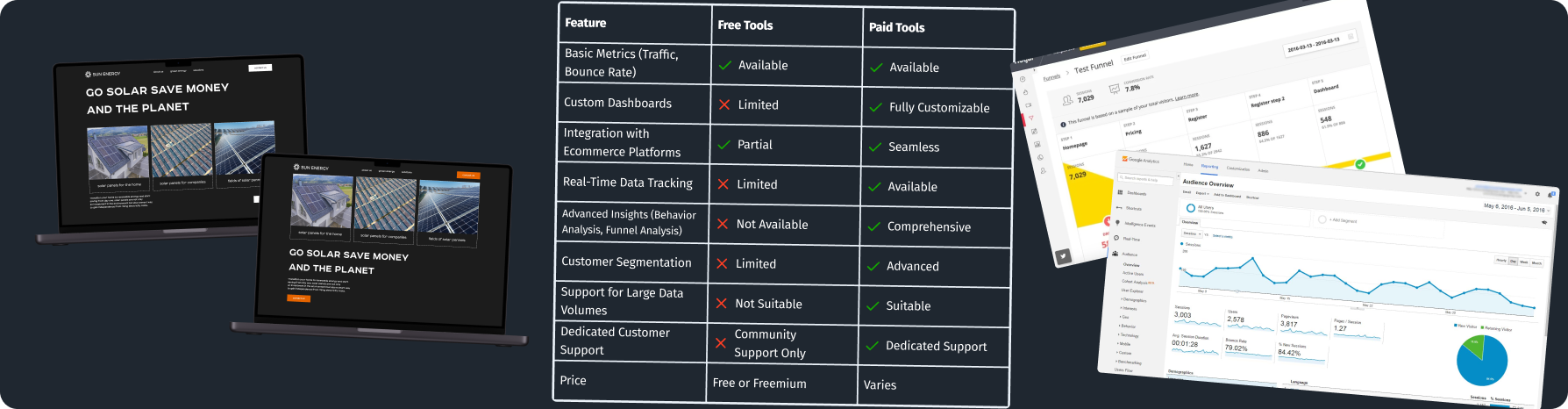
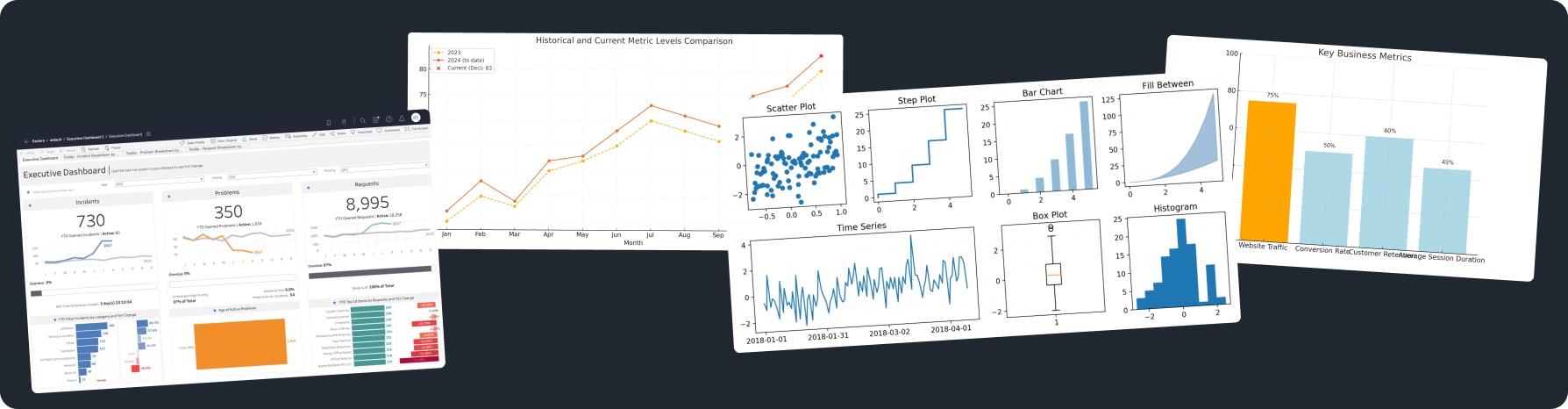
- Business Intelligence Software: Platforms such as Tableau, Microsoft Power BI, and QlikView automate data visualization and reporting, allowing for real-time insights and decision support systems.
- Data Workflow Automation Tools: Solutions like Apache Airflow, Prefect, and Luigi manage and schedule automated data pipelines, ensuring data is processed and available when needed.
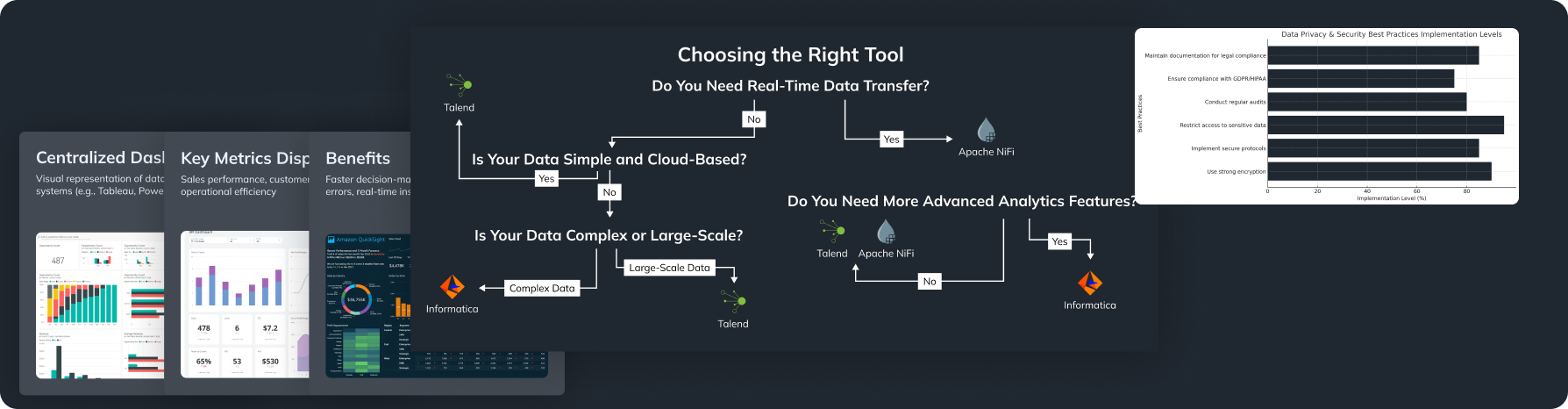
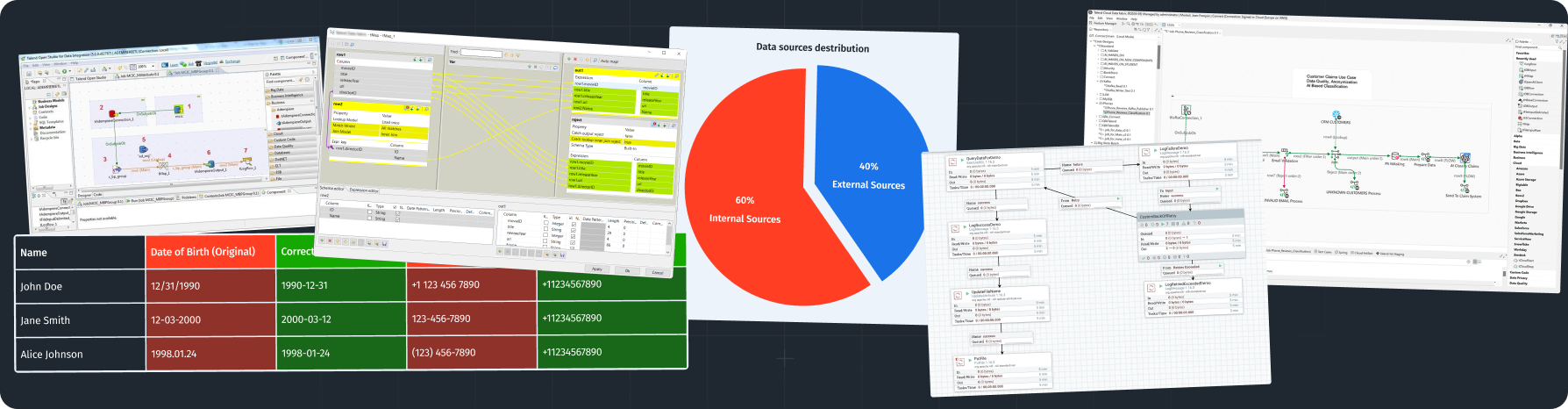
- Data Integration Tools: Services like Talend, Informatica, and Fivetran automate the integration of data from various sources, enhancing data quality and consistency.
- Robotic Process Automation (RPA): Tools like UiPath, Automation Anywhere, and Blue Prism automate repetitive tasks, freeing up human resources for more complex activities.
Techniques for Data Automation
Automation techniques in data science include:
- Automating Data Collection: Using web scraping tools like Scrapy and Beautiful Soup, and APIs to gather data efficiently from multiple sources.
- Data Cleansing Automation: Implementing scripts and tools such as Pandas and Dask that handle missing values, duplicates, and outliers to improve data quality.
- Model Building Automation: Employing AutoML platforms for selecting the best algorithms and tuning models without extensive manual intervention.
- Deployment Automation: Using continuous integration and continuous deployment (CI/CD) pipelines with tools like Jenkins, GitLab CI/CD, and Docker for deploying models into production environments seamlessly.
External Instruments to Consider
For organizations looking to implement data science automation, the following instruments can be highly beneficial:
- Alteryx: An end-to-end analytics platform that automates data preparation, blending, and advanced analytics.
- KNIME Analytics Platform: An open-source platform for creating data science workflows, integrating various tools and algorithms.
- AWS SageMaker: A fully managed service that provides the ability to build, train, and deploy machine learning models at scale.
- Azure Machine Learning: Microsoft’s cloud-based environment for training, deploying, and managing machine learning models.
- IBM Watson Studio: A platform that provides tools for data preparation, model development, and deployment in a collaborative environment.
Benefits of Automating Data Science Workflows
Data Efficiency Gains
Automation significantly speeds up data processing and analysis. Tasks that once took weeks can now be completed in hours, enabling teams to focus on strategic initiatives rather than routine tasks. This acceleration enhances productivity and allows organizations to respond swiftly to new opportunities or challenges.
Accuracy and Reliability
By minimizing human error, automation increases the reliability of data insights. Automated systems ensure consistent application of algorithms and methodologies, leading to more accurate results. This consistency is crucial for maintaining the integrity of analyses and making sound business decisions.
Scalability
Automation supports scaling operations without a proportional increase in resources. With cloud computing integration, organizations can handle larger datasets and more complex analyses effortlessly. This scalability is essential for growing businesses that need to adapt quickly to increasing data volumes.
Cost Savings
By streamlining processes and reducing manual labor, automation can lead to significant cost reductions. Organizations can reallocate resources to higher-value activities, such as strategic planning and innovation, enhancing overall competitiveness.
Challenges and Considerations in Data Science Automation
Complexity and Cost
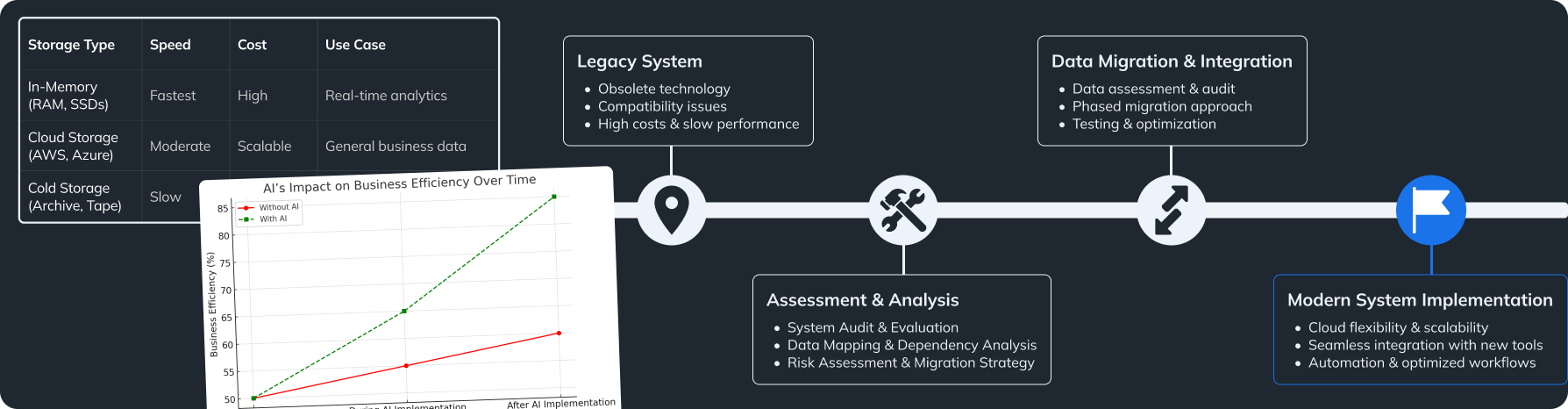
Implementing automation can be complex and may require significant upfront investment in tools and training. Organizations need to carefully assess the return on investment and plan accordingly. It’s essential to choose solutions that align with business goals and have a clear implementation roadmap.
Ethical and Security Issues
Automation introduces risks related to data privacy and security. Handling sensitive data requires robust security measures and compliance with regulations like GDPR or HIPAA. Ethical considerations, such as algorithmic bias, must be addressed to ensure fair and unbiased outcomes. Transparency in how automated systems make decisions is also critical to maintain trust.
Change Management
Transitioning to automated systems requires change management to address resistance from staff accustomed to manual processes. Training and clear communication are essential to facilitate adoption. Organizations should foster a culture that embraces technological advancements and continuous learning.
Future Trends in Data Science Automation
Emerging Technologies
- Artificial Intelligence Implementation: Integration of AI in automation tools will enhance capabilities, enabling more sophisticated analyses and decision-making processes.
- AutoML Advancements: Further developments in AutoML will simplify model building and deployment even more, making advanced analytics accessible to non-experts.
- Natural Language Processing (NLP): Automation tools will increasingly incorporate NLP to handle unstructured text data, opening new avenues for insights.
- Edge Computing: Processing data closer to its source will reduce latency and improve real-time analytics, especially important for Internet of Things (IoT) applications.
Industry Predictions
- Increased Adoption Across Industries: Sectors like manufacturing, healthcare, and finance will continue to adopt automation to stay competitive and meet growing data demands.
- Enhanced Operational Analytics: Organizations will leverage automation for real-time analytics, improving operational decision-making and responsiveness.
- Greater Emphasis on Explainability: As automation becomes more prevalent, there will be a focus on making automated processes transparent and explainable to stakeholders.
How to Implement Data Science Automation in Your Organization
Step-by-Step Guide
- Assess Current Workflows: Identify processes that are time-consuming and prone to errors. Evaluate where automation can have the most significant impact.
- Define Objectives: Set clear goals for what automation should achieve, such as reducing processing time, improving accuracy, or scaling operations.
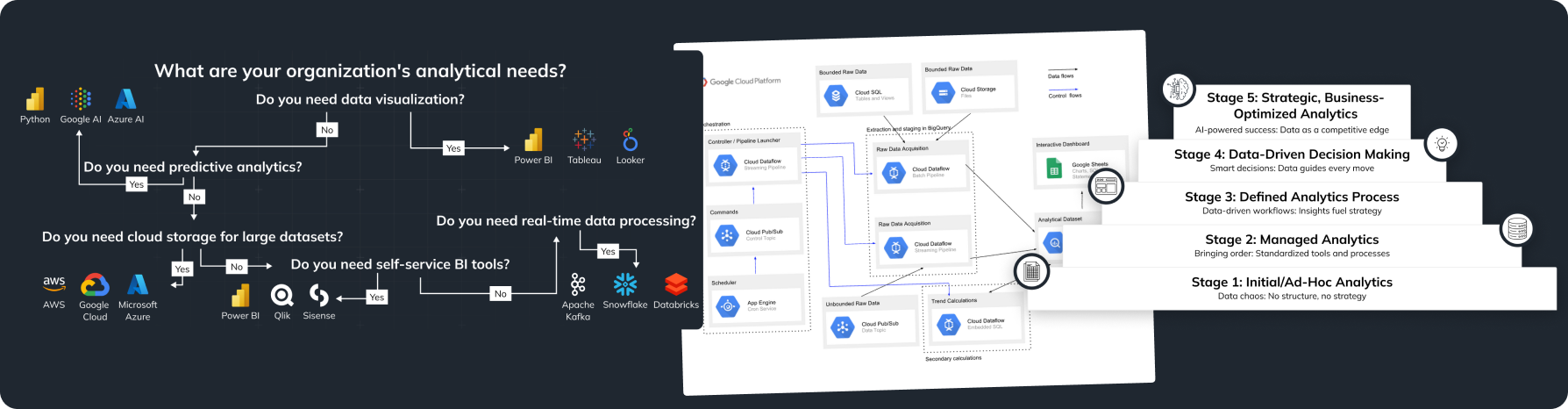
- Choose the Right Tools: Research and select tools that fit your organization’s needs and infrastructure. Consider factors like scalability, ease of use, and support.
- For data integration, consider Fivetran or Stitch Data.
- For machine learning, evaluate DataRobot or H2O.ai.
- For data visualization, tools like Looker or Power BI might be suitable.
- Develop a Pilot Project: Start with a small, manageable project to demonstrate the benefits of automation. Use this as a learning experience to refine your approach.
- Train Your Team: Invest in training to ensure staff are comfortable with new tools and processes. Encourage continuous learning and skill development.
- Integrate with Existing Systems: Ensure new automation tools can seamlessly integrate with current systems to avoid disruptions.
- Monitor and Evaluate: Continuously monitor performance and make adjustments as necessary. Gather feedback from users and stakeholders.
- Scale Up: Gradually extend automation to other areas of the organization, building on successes and lessons learned.
Key Factors to Consider
- Infrastructure: Evaluate whether your current IT infrastructure can support new automation tools, or if upgrades are needed. Consider cloud solutions for flexibility.
- Skills and Expertise: Assess the skill levels of your team and consider hiring or training to fill gaps. Collaboration between data scientists and IT professionals is crucial.
- Data Quality: Ensure that the data used is clean and reliable to maximize the effectiveness of automation. Implement data governance practices.
- Organizational Culture: Foster a culture that embraces innovation and continuous improvement. Leadership support is vital for successful adoption.
Case Studies from Dot Analytics
Case Study 1: Retailer Enhances Inventory Management with Automation
Challenge: A large retail company struggled with inventory management due to data silos and manual processes, leading to stockouts and overstock situations.
Solution: By implementing data science automation tools like Alteryx for data integration and Tableau for real-time visualization, they automated data collection from sales, suppliers, and warehouses. They used AWS SageMaker to build predictive models for demand forecasting. Machine learning models like XGBoost were employed for their accuracy in regression tasks.
Outcome: This enabled real-time inventory tracking and accurate demand forecasting. As a result, they reduced stockouts by 30% and decreased excess inventory by 20%, leading to significant cost savings and improved customer satisfaction.
Case Study 2: Financial Institution Improves Fraud Detection
Challenge: A financial institution faces challenges in detecting fraudulent transactions promptly due to the sheer volume of transactions and sophisticated fraud techniques.
Solution: They adopted automated data science techniques by implementing H2O.ai’s AutoML to analyze transaction data in real time. They also used Apache Kafka for real-time data streaming and Apache Spark for big data processing. Machine learning models such as Random Forest and Deep Learning Neural Networks were utilized for their effectiveness in classification tasks.
Outcome: By integrating advanced analytics capabilities and achieving machine learning efficiency, they developed models that automatically flagged suspicious activities. This automation reduced fraud detection time from days to minutes and decreased financial losses by 40%, enhancing trust with their customers.
Case Study 3: Healthcare Provider Streamlines Patient Care
Challenge: A healthcare provider aimed to improve patient care by analyzing electronic health records (EHR). Manual data processing was time-consuming and error-prone, affecting the ability to make timely decisions.
Solution: By automating data extraction and analysis using IBM Watson Health and Python libraries like Pandas and Scikit-learn, they could predict patient readmission risks and personalize treatment plans. They utilized Natural Language Processing (NLP) techniques, specifically SpaCy and NLTK, to extract information from unstructured clinical notes. Machine learning models like Logistic Regression and Support Vector Machines (SVM) were employed for predictive analytics.
Outcome: This led to a 25% reduction in readmission rates and improved patient outcomes, demonstrating the power of data-driven healthcare solutions.

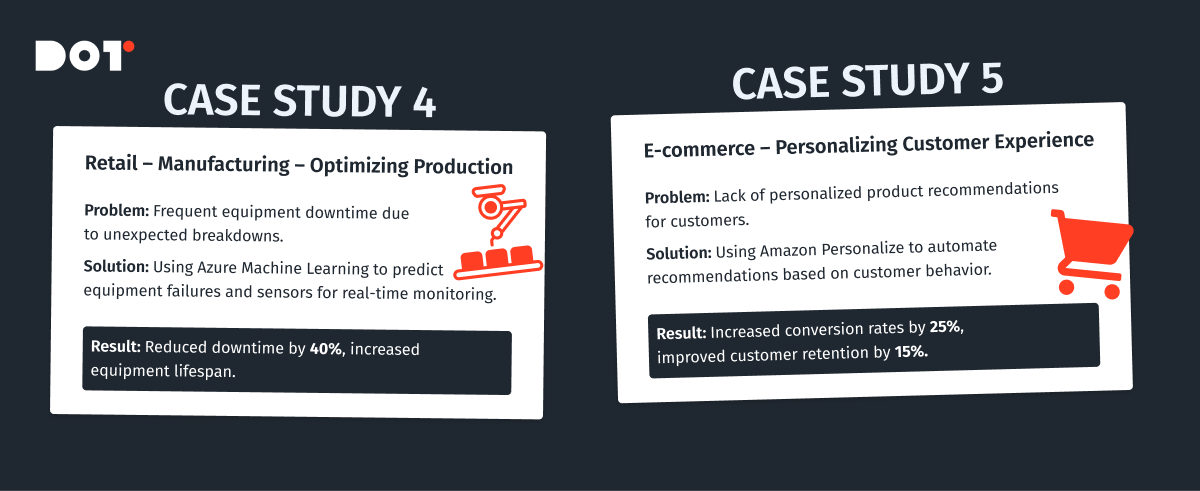
Case Study 4: Manufacturing Company Optimizes Production with AI
Challenge: A manufacturing company faced inefficiencies in production due to equipment downtime and maintenance issues.
Solution: They implemented Azure Machine Learning to develop predictive maintenance models. Sensors on equipment provided real-time data, which was analyzed using machine learning algorithms like Time Series Analysis and Anomaly Detection models. Tools like TensorFlow and Keras were used for building deep learning models to predict equipment failures before they occurred.
Outcome: The company reduced unplanned downtime by 40%, increased equipment lifespan, and improved overall production efficiency, resulting in significant cost savings.
Case Study 5: E-commerce Platform Enhances Customer Experience
Challenge: An e-commerce company wanted to improve customer experience by providing personalized product recommendations but struggled with manual data processing and analysis.
Solution: They adopted automated data science tools like Apache Mahout and Amazon Personalize to build recommendation systems. Machine learning models such as Collaborative Filtering and Content-Based Filtering were utilized to analyze customer behavior and preferences.
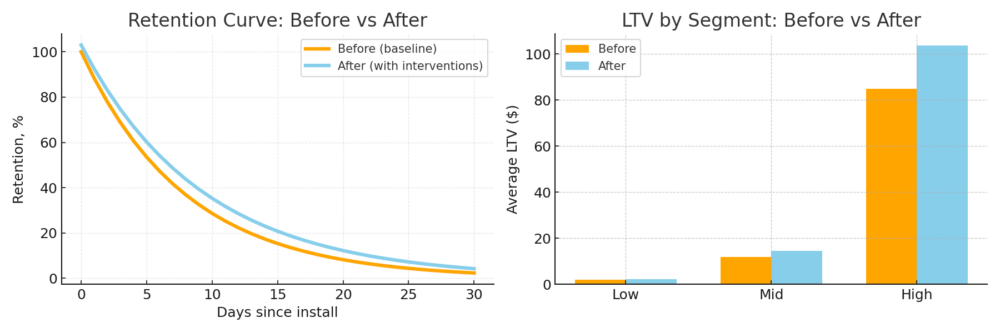
Outcome: Personalization efforts led to a 25% increase in sales conversions and a 15% boost in customer retention rates, highlighting the impact of automated data science on customer engagement.
Conclusion and Call to Action
Data science automation is transforming how organizations handle data, offering increased efficiency, accuracy, and scalability. While challenges exist, the benefits of automating data workflows far outweigh the risks. By embracing automation, businesses can stay ahead in a competitive landscape, making data-driven decisions more quickly and effectively.
Do you fully understand the topic? If not, you can book a free 15-minute consultation with an expert from Dot Analytics.
Ready to take the next step in automating your data science workflows? Contact us today to explore customized solutions for your organization.




















Leave a Reply